目次
先に音を確認したい方はこちらから👉examples
概要

本研究では、ウェーブテーブル合成1と呼ばれる音響合成方式において、深層生成モデルを用いて意味的な音色制御を行う手法を提案する。 ウェーブテーブル合成とは、1周期分の波形(以下、ウェーブテーブルと称する)を繰り返し読み出す事で音響合成を行う方式である。
提案手法では、Conditional Variational Autoencoder (CVAE) 2を用いて、ウェーブテーブルの条件付け生成を行う。 条件付けには、音響特徴に基づいて算出した明るさ(bright), 暖かさ(warm), リッチさ(rich)という3つの意味的なラベルを用いる。 また、ウェーブテーブルの特徴を捉えるために、畳み込みとアップサンプリングを用いたCVAEのアーキテクチャを設計する。 これらは、リアルタイム性を高めるために推論時に周波数領域に変換せずに実行可能とする。
実験には、Adventure Kid Research & Technology 3が提供するモノラルのウェーブテーブル4158件をデータセットとして用いる。 実験の結果、提案手法は意味的なラベルを変化させることでウェーブテーブルの音色をリアルタイムに操作できる事を定性的・定量的に示す。 本研究は、データに基づいた意味的なウェーブテーブル制御の実現による音色探索の直感性向上を目的する。
序論
音楽制作やパフォーマンスにおいて、シンセサイザーは重要な役割を果たしている。 しかし、望む音色を生成するためには、知識と経験が必要である。 多くの音響合成方式が存在するが、ここではデジタル音響合成の最小単位である「ウェーブテーブル合成」に注目し、 データに基づいた意味的なウェーブテーブル制御を実現する。 この方法は、1周期分の波形を対象とする事で、ウェーブテーブル合成及び加算/減算合成,AM/FMなどの他合成方式にも適用できるものとする。
方法
Wavetable Synthesis

- デジタル音響合成の基礎となる技術
- 1周期分の波形(ウェーブテーブル)を保存し繰り返し読み出す事で音を生成
- 繰り返し速度を変える事で任意の音高を出力する
▶︎参考動画(クリックで開く)
CVAE(Conditional Variational Autoencoder)
- Encoder-Decoderネットワークに基づいた、確率分布からサンプリングされた潜在変数を持つ生成モデルの一種
- 入力データに対して条件付きで生成を行うことが可能
関連研究
Kreković4は、オートエンコーダーを用いて知覚に基づいたラベルからウェーブテーブルを生成している。 しかし、同研究においては、ウェーブテーブルのサイズを3つのパラメタに圧縮し、 オートエンコーダーのデコーダー部分のみを用いて生成を行うという手法が用いられており、生成の多様性に制限がある。 また、Hyrkasら5は、ランダムにウェーブテーブルの潜在空間を探索することで音色の操作を試みたが、音色の特徴を表現するパラメタを使用することができず、 操作の自由度や直感性が制限されている。 本研究では、これらの課題を解決し、より直感的かつ多様な音色の生成を実現するために、 CVAEを採用し意味的なラベルでの条件付け生成を行う手法を提案する
提案手法

①. データセット
- Adventure Kid Research & Technology3が提供しているモノラルのSingle Cycle Waveformを使用
- データ長は600[sample]であり、先行研究と比較して45解像度が高いものを採用
②. 教師ラベルの算出
- Wavetableの分析は、静的音色について表される音響特徴量を用いる必要がある
- Kreković4は、明るさ(bright), 暖かさ(warm), リッチさ(rich)の3種類の意味的なラベルをそれぞれ、スペクトル重心、スペクトル密度、奇数時倍音のエネルギー比から算出
- 本研究でも同様の手法を使用しデータセットからラベルを抽出し学習と生成に用いる
静的音色:時間的な変化のない音(定常音)について、周波数スペクトルによって規定される音6
▶︎ラベルの分布と相関の図(クリックで開く)

③. モデル構成
- 波形の時間依存性を捉えるために、 畳み込みとアップサンプリングを行うモデルを設計
- 潜在変数の入力と出力部分で条件付けを実施
- リアルタイム性を高めるために推論時に周波数領域に変換せずに実行可能とする
▶︎モデル構成詳細(クリックで開く)
④. 損失関数
- 音響信号は位相が異なっていても同じスペクトルを得る事がある
- 特徴を正確に捉える為にSTFT(Short Term Fourier Transform)を行い、スペクトルからロスを計算
- スペクトルの分解能を上げる為に、6つ分のウェーブテーブルを連結し、下記のスペクトル距離を使用
実験
実験目的
- 再構成誤差の最小化と条件付け精度と滑らかさを実現するモデルの検証
- 提案手法の有効性を定性的・定量的に確認
条件
- 学習率は0.001、Adam optimizerを使用
- バッチサイズは32
- エポック数は30000回
結果
再構成品質
- 再構成品質と条件付け生成の結果を確認
- 条件付けラベルと出力ウェーブテーブルの特徴量の平均絶対誤差(MAE)を算出
examples
- 意味的なラベルによる合成の結果を以下に示す(サンプル音あります)
- 元になるWavetableをモデルに入力(入力Wavetableの詳細は上記参照)
- 明るさ、リッチさ、暖かさをそれぞれ3段階の値(0,0.5,1.0)で条件付け生成し楽曲にて確認
(折りたたみのタブになっているのでクリックすると展開されます。)
▶︎sine_wave
| Condition value | 0 | 0.5 | 1.0 |
|---|---|---|---|
| 明るさ(bright) | 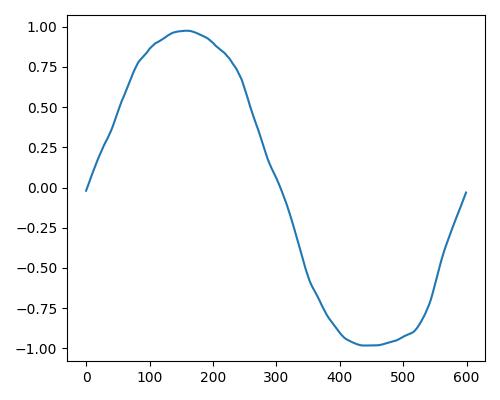 |
 |
 |
| Estimate value | b=0.109, r=0.112, w=0.00 | b=0.277, r=0.305, w=0.193 | b=0.374, r=0.444, w=0.813 |
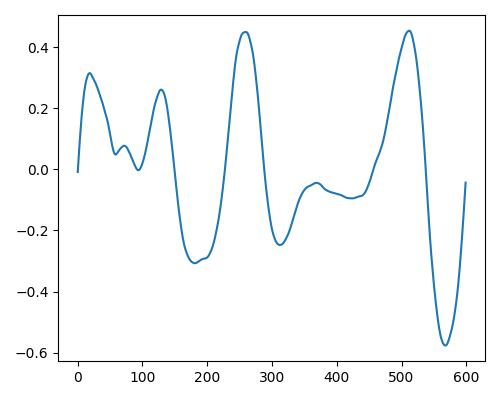
| リッチさ(rich) | 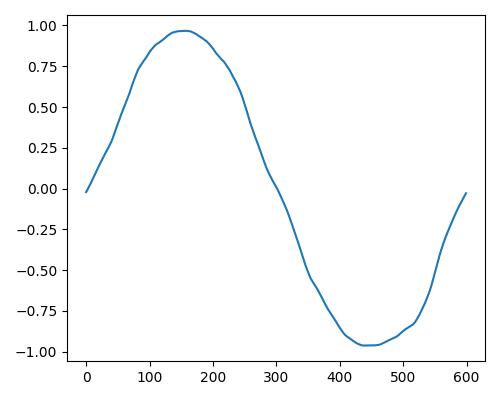 |
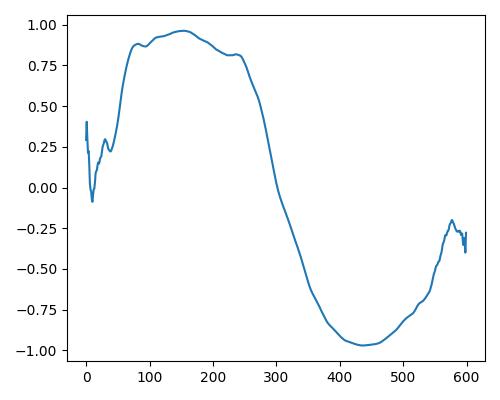 |
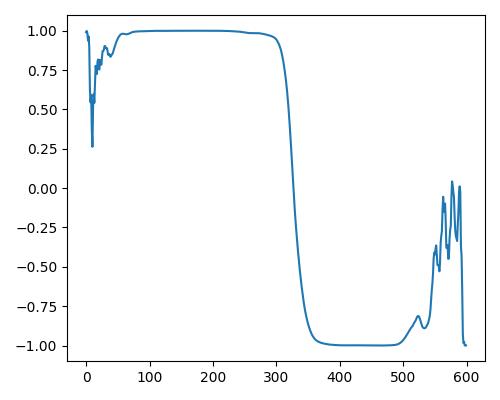 |
| Estimate value | b=0.109, r=0.115, w=0.00 | b=0.124, r=0.421, w=0.012 | b=0.198, r=0.559, w=0.083 |
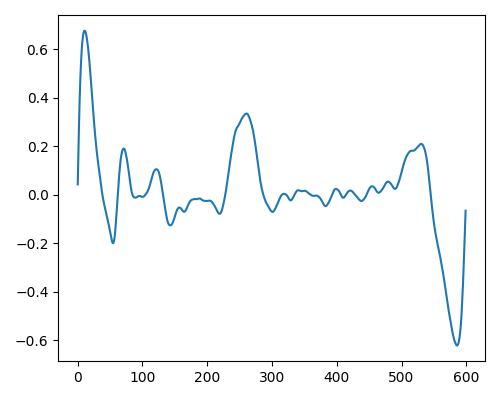
| 暖かさ(warm) | 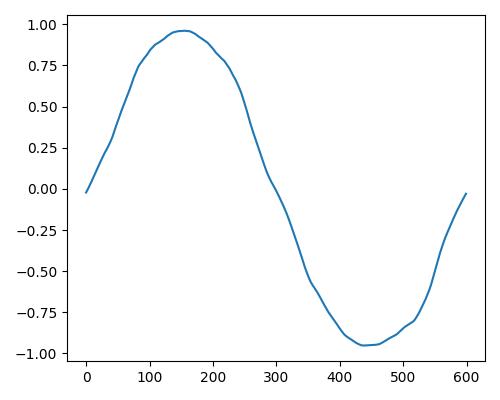 |
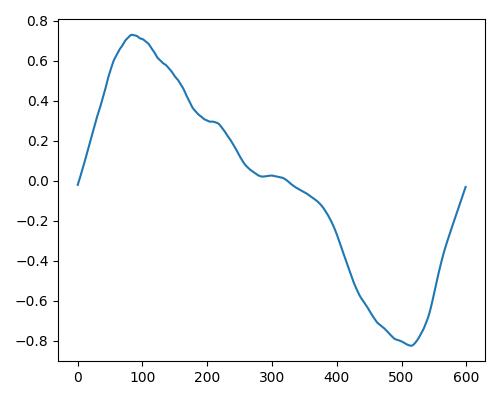 |
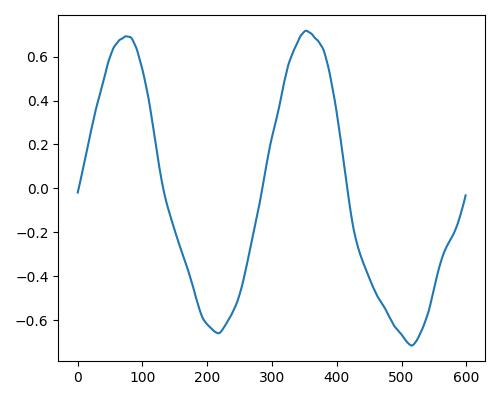 |
| Estimate value | b=0.109, r=0.117, w=0.00 | b=0.143, r=0.204, w=0.450 | b=0.173, r=0.180, w=0.889 |
▶︎square_wave
| Condition value | 0 | 0.5 | 1.0 |
|---|---|---|---|
| 明るさ(bright) | 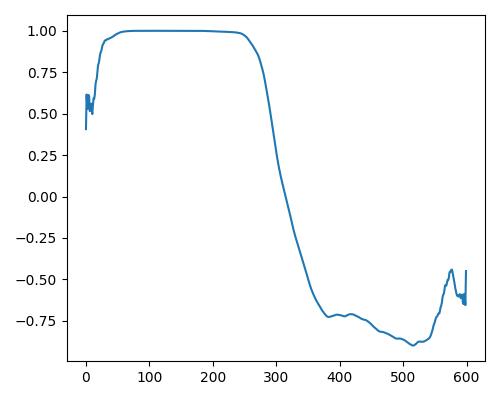 |
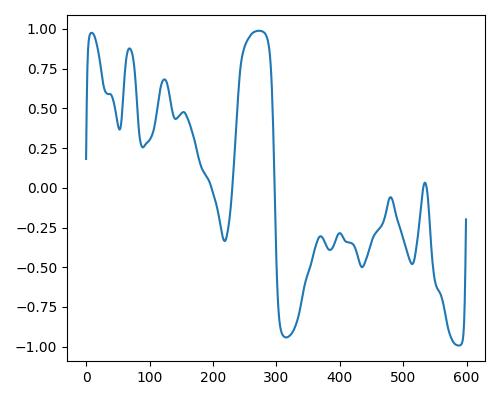 |
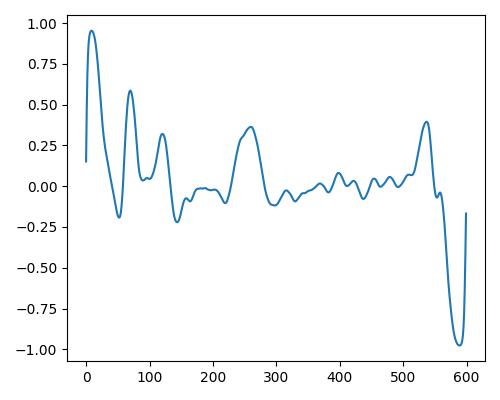 |
| Estimate value | b=0.140, r=0.433, w=0.233 | b=0.280, r=0.426, w=0.178 | b=0.352, r=0.465, w=0.632 |
| リッチさ(rich) | 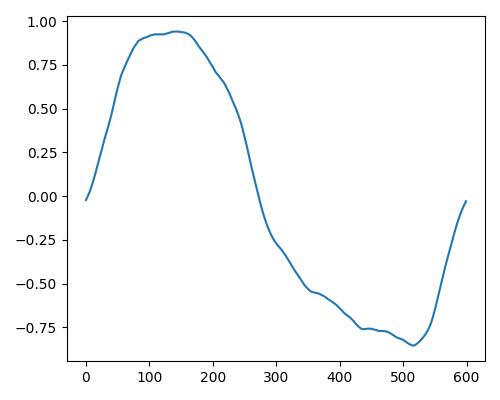 |
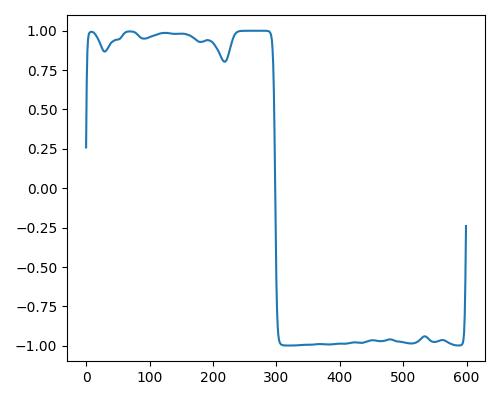 |
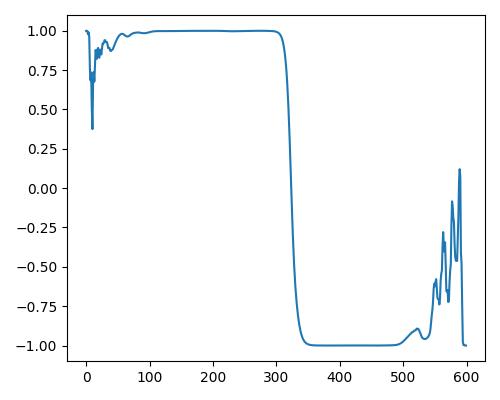 |
| Estimate value | b=0.109, r=0.140, w=0.00 | b=0.176, r=0.419, w=0.064 | b=0.195, r=0.549, w=0.127 |
| 暖かさ(warm) | 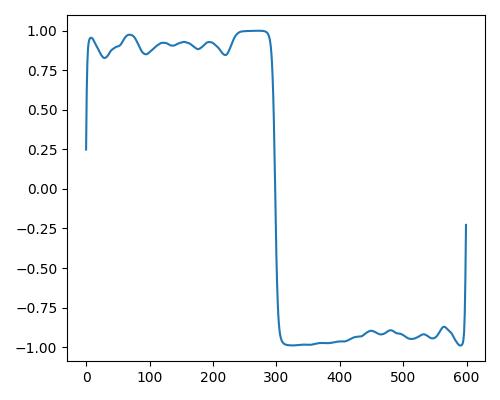 |
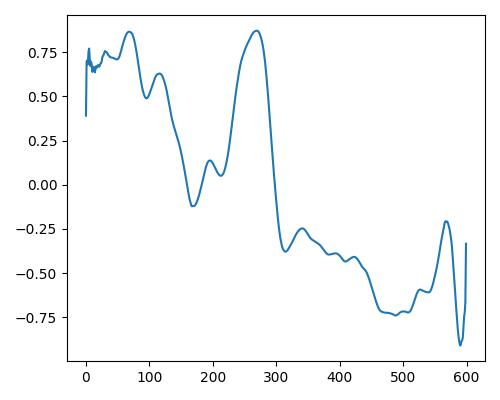 |
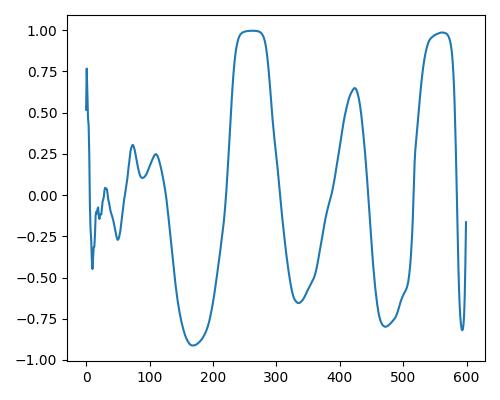 |
| Estimate value | b=0.151, r=0.441, w=0.032 | b=0.226, r=0.466, w=0.517 | b=0.297, r=0.483, w=0.886 |
▶︎distorted_wave1
| Condition value | 0 | 0.5 | 1.0 |
|---|---|---|---|
| 明るさ(bright) | 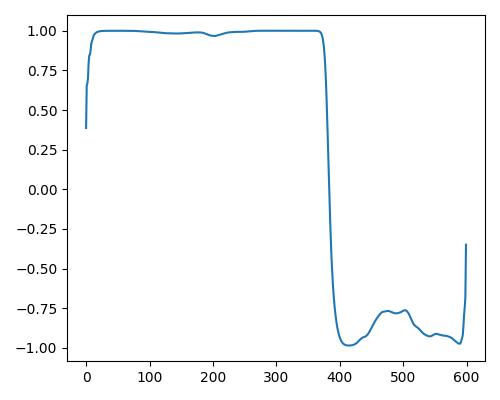 |
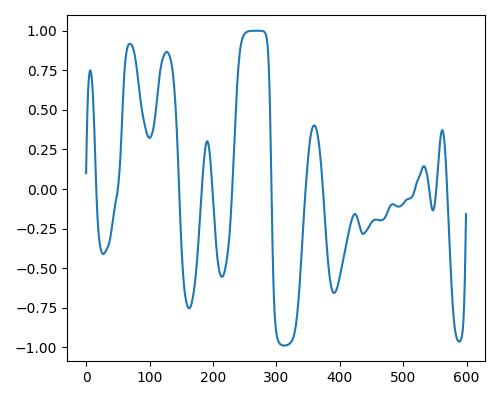 |
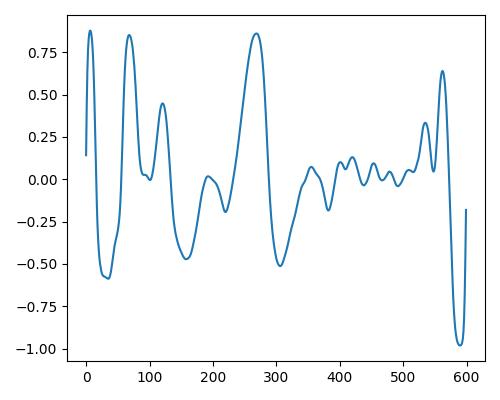 |
| Estimate value | b=0.123, r=0.413, w=0.306 | b=0.323, r=0.451, w=0.620 | b=0.390, r=0.481, w=0.905 |
| リッチさ(rich) | 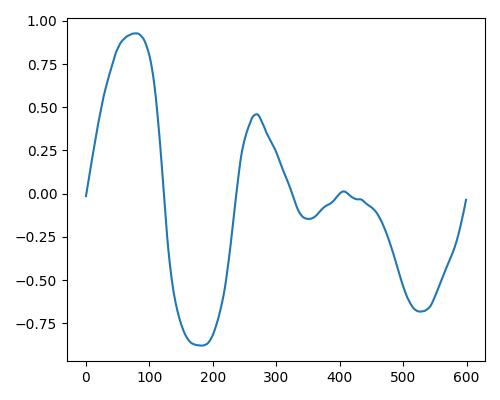 |
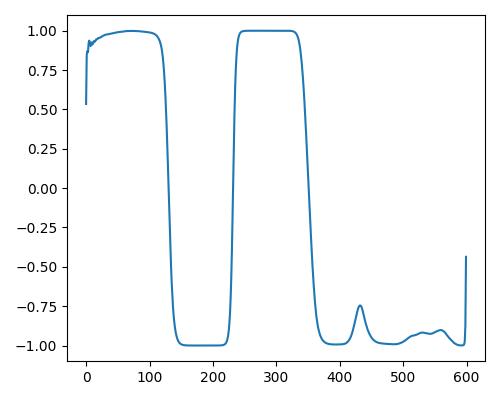 |
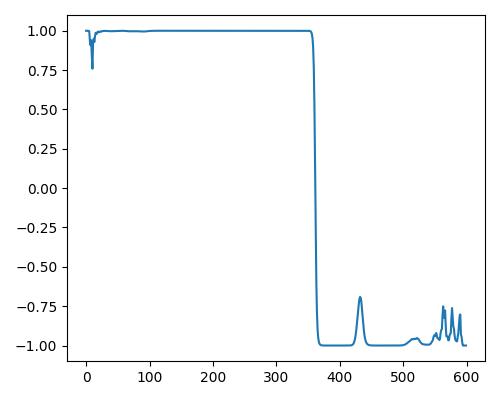 |
| Estimate value | b=0.200, r=0.260, w=0.600 | b=0.250, r=0.450, w=0.533 | b=0.214, r=0.544, w=0.235 |
| 暖かさ(warm) | 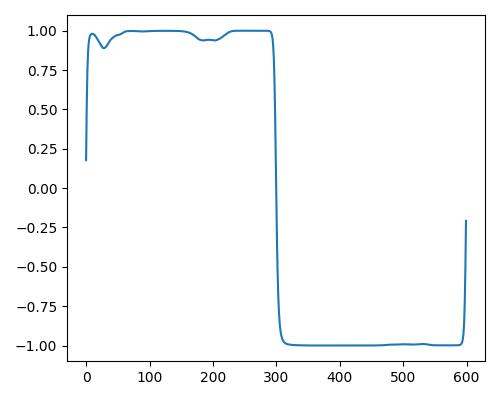 |
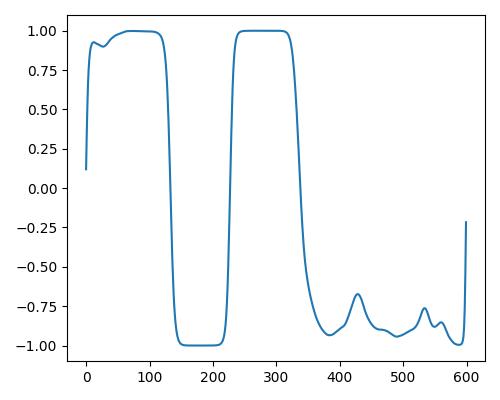 |
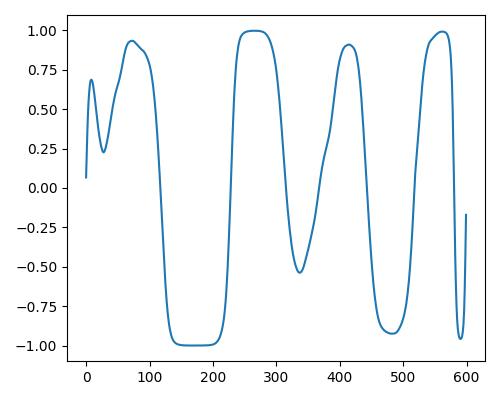 |
| Estimate value | b=0.162, r=0.385, w=0.045 | b=0.223, r=0.404, w=0.461 | b=0.250, r=0.551, w=0.817 |
- グラフは縦軸が振幅、横軸がデータ長
- b=bright, r=rich, w=warm
- Prelude of Suite No. 1 in G major, BWV 1007, J.S. Bachを使用
推論時間
本研究では、Apple M1 MacBook Pro(2020) CPUを使用し、pytorch-lightning 1.7.7で推論時間を計測した。 その結果、推論時間は約2.6[ms]であった。この推論時間は、西ら9によって示された弁別しやすい音(スネアドラムとピアノ)において認知される遅延時間である30[ms]の1/10程度であり、リアルタイムに十分に使用できる可能性を示す。
まとめ
考察・今後の展望
本研究では、ウェーブテーブル合成における意味的な音色制御を可能にする手法を提案し、 特に、ラベルを変化させることで、ウェーブテーブルの音色を操作することができることを示した。 ただし、再構成精度やラベルの効き具合や滑らかさ、潜在空間がもつれた表現になっているなどの課題が残っている。
また、提案手法では、音響特徴に基づいて算出した3つのラベルを用いた条件付け生成を行った。 しかし、ラベルの種類や数を増やすことで、より細かい音色の制御が可能となると考えられる。 今後は、より多様なラベルを用いた音色制御の実現を目指すことが重要である。
データセットとして、モノラルのウェーブテーブル4158件を使用したが、 データセットの増加によって、より多様な音色の生成や条件付けが可能となると考えられる。 今後は、より多様なウェーブテーブルを含むデータセットの構築が求められる。
また、生成された音色の評価指標として、 人間の主観的な評価や音響特徴を用いた客観的な評価が必要であり、 今後、検討を進める必要がある。
UI案

潜在空間の操作部分をNistalら10を参考にデザインした
▶︎おまけ:DAW上での使用イメージ(クリックで開きます)

謝辞
This work was supported by Cybozu Labs youth.
参考文献
-
Robert Bristow-Johnson, “Wavetable synthesis 101, a fundamental perspective,” in Audio Engineering Society Convention 101. Audio Engineering Society, 1996. ↩
-
Kingma, Durk P., et al. “Semi-supervised learning with deep generative models.” Advances in neural information processing systems 27, 2014. ↩
-
“Adventure Kid Research & Technology (AKRT)” https://www.adventurekid.se/akrt/ ↩ ↩2
-
Kreković, Gordan. “DEEP CONVOLUTIONAL OSCILLATOR: SYNTHESIZING WAVEFORMS FROM TIMBRAL DESCRIPTORS.” Sound and Music Computing, 2022. ↩ ↩2 ↩3
-
Hyrkas Jeremy. “WaVAEtable Synthesis” Computer Music Multidisciplinary Research (CMMR) 2021. ↩ ↩2
-
岩宮眞一郎:音響サイエンスシリーズ1 音色の感性学, コロナ社,pp.64-67, 2010. ↩
-
Engel, Jesse, et al. “DDSP: Differentiable digital signal processing.” In International Conference on Learning Representations, The International Conference on Learning Representations, 2020. ↩
-
Caillon, Antoine, and Philippe Esling. “RAVE: A variational autoencoder for fast and high-quality neural audio synthesis.” arXiv preprint arXiv:2111.05011, 2021. ↩
-
西堀佑, 多田幸生, and 曽根卓朗. “遅延のある演奏系での遅延の認知に関する実験とその考察.” 情報処理学会研究報告音楽情報科学 (MUS) 2003.127 2003-MUS-053, 2003. ↩
-
Nistal, Javier, et al. “DrumGAN VST: A Plugin for Drum Sound Analysis/Synthesis with Autoencoding Generative Adversarial Networks.” arXiv preprint arXiv:2206.14723, 2022. ↩